모놀리식 관제를 분해한 이유: AWS IoT + Firehose + OpenSearch 파이프라인 설계
초기 관제 시스템은 단일 서버에서 데이터 수집, 변환, 분석, 연동을 모두 처리했다. 초기에는 빠르게 기능을 붙일 수 있었지만, 로봇 대수와 요구사항이 늘면서 병목과 장애 전파가 반복됐다.
이 글은 그 구조를 AWS IoT Core/Rules + Data Firehose + Lambda + S3 + Elasticsearch로 분리한 이유와 구현 포인트를 정리한 기록이다.
문제 정의
운영에서 반복적으로 부딪힌 문제는 아래 네 가지였다.
- 특정 처리 로직의 병목이 전체 서비스 성능 저하로 이어짐
- 수집 로직 변경이 분석/조회 로직까지 연쇄적으로 영향
- 단일 서버 장애 시 전체 데이터 처리 경로가 함께 중단됨
- 기능 개발보다 운영/복구 작업에 엔지니어링 시간이 더 소모됨

설계 목표
- 운영 부담이 낮은 완전 관리형 서비스 기반으로 구성
- 수집/변환/적재 경로를 분리해 장애 전파 범위 축소
- 재처리 가능한 경로를 확보해 데이터 유실 리스크 완화
- 외부 서비스 연동 비용(코드 수정/재배포) 최소화
아키텍처 선택
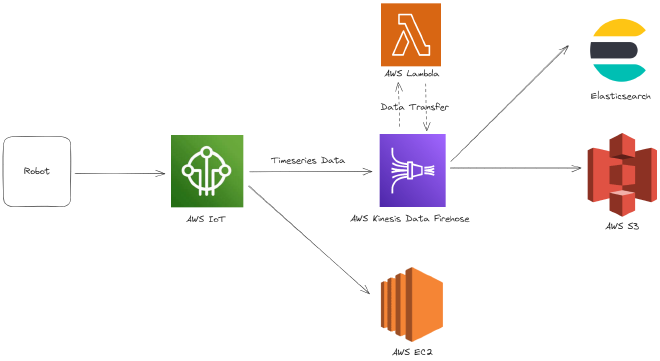
1) 수집: AWS IoT Core + Rules
로봇에서 MQTT/HTTP로 발행한 데이터를 IoT Core에서 수집하고, Rules로 라우팅해 후속 처리 서비스로 전달했다.
2) 변환/적재: Amazon Data Firehose + Lambda
Data Firehose를 중심으로 스트림을 구성하고, SQL만으로 어려운 레코드 변환은 Lambda에서 수행했다.
- 실시간 검색 경로: Elasticsearch/OpenSearch
- 장기 보관/배치 분석 경로: S3
3) 검색 운영: ILM/Template
색인 전처리와 수명주기를 분리했다.
- ingest pipeline: 적재 전 필드 정규화
- ILM: rollover/delete 정책으로 보관 주기 관리
- index template: 인덱스 설정 일관성 유지
왜 KDS/MSK 대신 Firehose였나
당시 의사결정의 기준은 “최대 유연성"이 아니라 “운영 단순성 + 충분한 처리 성능"이었다.
- KDS: 유연하지만 샤드/파티션 운영 복잡도가 큼
- MSK: 강력하지만 클러스터 운영 오버헤드가 큼
- Firehose: 서버리스 운영, 목적지 직접 적재, IoT Rules 연동이 단순
제한된 인력으로 빠르게 안정화해야 했기 때문에 Firehose가 현실적인 선택이었다.
구체 설정 예시
Firehose는 버퍼 크기/시간을 같이 설정해야 한다.
BufferingHints:
SizeInMBs: 10
IntervalInSeconds: 60
이 값은 “지연"과 “목적지 부하"를 같이 바꾼다.
- 너무 작으면 호출 수가 급증
- 너무 크면 분석 지연이 커짐
Lambda 변환을 붙인 경우에도 버퍼 정책을 별도로 조정해야 레코드 배치 효율이 유지된다.
적용 결과
- 관제 서버의 복잡도와 장애 전파 범위 축소
- 실시간 검색과 장기 분석 경로 동시 확보
- 운영 인력 대비 확장성 개선
한계와 다음 단계
이 구조는 초기/중간 규모에서는 매우 효율적이지만, 로봇 대수와 이벤트 볼륨이 계속 증가하면 비용 최적화 한계가 나타난다.
장기적으로는 고처리량 워크로드 일부를 Kafka 계열로 분리하는 하이브리드 구조를 검토하고 있다.
참고 및 인용
참고: Amazon Data Firehose는 스트리밍 데이터를 대상 저장소로 서버리스 적재하는 관리형 서비스다. What is Amazon Data Firehose?
참고: AWS IoT Rules 액션은 IoT 메시지를 Firehose 등으로 라우팅할 때 사용된다. AWS IoT rule actions
참고: Elasticsearch ILM은 인덱스 수명주기(rollover/delete) 자동화를 위한 표준 메커니즘이다. Index lifecycle management